pointertovoid
Content Type
Profiles
Forums
Events
Everything posted by pointertovoid
-
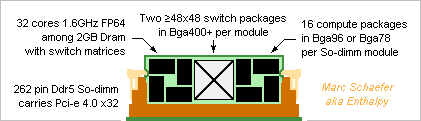
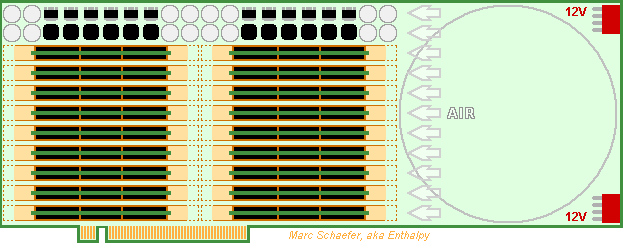
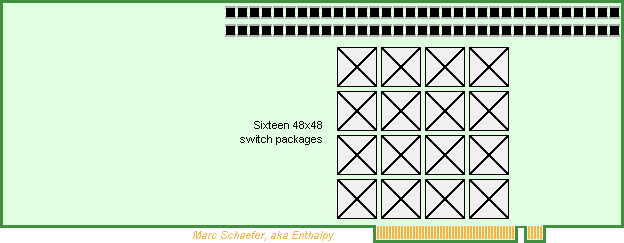
Using the already described technologies, a Pci-e number cruncher card can make money until supercomputers reuse its development effort. Here's a competitor to Nvidia's Hopper (30TFlops on 64b MAdd) and Amd's Instinct M210 (22.3TFlops as Pci-e card), much easier to program efficiently. 64b 1.6GHz scalar cores with FP64 MAdd compute everything. No Sse, Avx nor HT. Mmx-style parallelism welcome for vector 60TFlops FP32, 120TFlops FP16, INT32, Int16, Int8. A core uses the same power and area to multiply 2*2 32b numbers for matrix 120TOps, 4*4 16b 480TOps, 8*8 8b, and accumulate the columns, as complex numbers too. Enough complexity for the instruction set, sequencer, the compiler, the programmer! Consider faster 32b cores taking a few cycles on 64b. Arm, i64, a64, Mips, Risc, Sparc... make little difference. 32 such cores and chips access 1/32 of a 2GB Dram chip in one compute package, as already described. The MI210 and the Hopper offer only 8MB/core at identical Flops. Scaled as the Flops, 64MB Dram make 2GB for a 3GHz Avx256 quad-core, but 8MB make only 1/4 GB behind one Pci-e connector. The Dram provides 3*read+1*write/MAdd throughput for easy programming, plus the already described data shuffling for Fft and database. The Hopper's Dram reads or writes 0.1 FP64/MAdd and the MI210's 0.05. The cores have registers and L1 but no L2, L3... thanks to snappy Dram. 64 cores at 0.8GHz would cut the latency /4. The cores communicate over full switch matrices in a compute package. The Dram can integrate several >32*32 matrices or carry switch chips identical to the ones packages for the boards. For instance 8 parallel matrices at 16GT/s transfer one 64b data every core cycle between every core pair simultaneously. Alas, the boards carry fewer lanes, so the compute packages communicate with the outer world over their internal matrices for flexible bandwidth allocation, as in a fat tree network. The matrices, possibly Asics, communicate per Pci-e to serve between recycled Xeons too. 2GB/s Pci-e 4.0, of if possible Pci-e 5.0. A >48*48 full switch matrix takes little silicon in a Bga400+ and can use smaller packages where fewer lanes suffice. Each matrix connects all compute packages on one module, two matrices route x6 parallel lanes, this carries only 1 word per compute package in 1 cycle, or if spread evenly, 1 word per core in 34 cycles. The address is sent first, and upon knowing it, the matrices forward the data. Error detection happens later. The smallest message, about 64b, is but bigger than an address. The number of lanes used, sometimes over indirect paths, depends on the message size. Add operation modes to the Pci-e standard. The connector carries x32 lanes, So-dimm are denser. At least Amphenol sell vertical ones. 64GB/s provide 1 word per compute package in 3.2 cycles, or 1 word per core in mean 100 cycles. Each compute package passes x2 lanes through the connectors: the matrices first spread big messages among the compute packages. 18 modules fit on a double-slot Pci-e card to pack 9216 cores, 30TFlops and 0.56TB. The centrifugal blower cools easily 2W per compute package but 576W is much for one card. At the card's center, the blower would be quieter and ease routing but inject 300W heat in the tower. Each matrix connects the 18 modules, 16 matrices route x32 parallel lanes. Procuring standard Ddr5 2GB chips would cost 1.5kusd according to module price on eBay while the competing cards sell for 10kusd. Stacked Dram doubles the capacity but quadruples the cost, 1GB Dram costs half as much: product line. The tiny core chips are cheap and easily made. The matrices should add little and may well exist already. Marc Schaefer, aka Enthalpy aka Pointertovoid

-
That were 1kU chips at a reseller. As deduced from new Ddr5 modules on eBay, chip price is 1/3 that, or 60usd per Lga3647 for 24GB, and more capacity is conceivable. So eight Lga3647 per compute board make sense.
-
On 13 April 2023 and before, I wanted to cram eight Lga2011 or Lga3647 on a compute board, but unused Dram costs a lot, more Cpu share the throughput with the backplane, power supply is unusual. Six ddr4 channels cost 180usd per Lga3647 for 24GB only. Then a used Cpu can cost 200usd, chips for a compute board 4kusd, for a computer 4MUsd, plus more costs. At that price, Lga2011 Cpu (E7-8890 V4, E7-8895 v3, E5-2696 v4, E5-2698 v4, E5-2697 v4, E5-2695 v4) offer ~22 cores at 2.2GHz * Avx256. The 768*8 Cpu computer cumulates theoretical 2.4PFlops. Lga3647 Cpu (Xeon platinum 8124) offer ~26 cores at 2.0GHz * Avx512. The 768*8 Cpu computer cumulates theoretical 5.1PFlops, right at the Top500 list. But each Avx512 core owns 1GB only, scaling like 2GB for a quad-core Avx256. The Dram and network throughput are bad, the specific consumption too. I hope a manufacturer can make a bigger backplane Pcb instead, 1m*2m or more. Cost and performance justify an effort. ========== Chips update Did chips improve from January 2022 to May 2023? Msfn on 17 January 2022, 00:38 am ----- Dram update 2GB = 16Gb Dram are mass-produced. 4GB stack two chips and cost 4* as much per package, 1GB and 0.5GB 1/2 as much. 8GB (Micron, how many chips?) cost 16* as much as 2GB. ----- Flash update Micron, Kioxia, Samsung and Hynix produce 3D-Nand Flash, others maybe too. Samsung and Hynix seem to sell only complete Ssd, not chips I believe servers and number crunchers should use SLC chips if brazed. Micron offers 32GB. Mlc, Tlc, Qlc should be removable, then several compute chips can share 64GB-1TB and several GB/s. One flash chip in every compute package is damn seducing. Or a stack serving few compute packages. ----- Cpu update Intel is stuck at 14nm, or for smaller chips 10nm. But Tsmc and Samsung produce 5nm processors, others maybe too, which saves power, lets integrate more cores, even accelerates the clocks. ========== Divided Dram, split Cpu I'm still enthusiastic about stacking the Cpu and the Dram to pass thousands of signals. Tiny pads that consume very little, assigned after the imprecise alignment as already described. Contact or capacitance. But the Dram on top seems better. It saves the vias and acts as a perfect heat spreader for the tiny Cpu. 7nm Cpu dissipate some 0.12W at 1.8GHz, so cooling is very easy. More Cpu and slower clocks would save power further, they also reduce the latency of the smaller Dram, more so when counter in Cpu cycles. As it looks, 2GB Drams are already divided in 16 subgroups, so 16 Cpu on 1 Dram chip would suffer from the bad latency. I hope that each 1/16 Dram can be divided further and its signals routed by the Bga's printed circuit, which is much faster than lines on silicon. If for instance cutting in 4 reduces the latency from 20ns to 5ns, about 5 processor cycles, then the Cpu has only a data L1, an instruction L1 and registers. The scalar 64b Cpu without HT is then really small. Micron and others can make the redesigned Dram. Intel, Chinese manufacturers and many more can make the Cpu, including at 14nm, but 7nm or 5nm save power or can run faster. That is, many countries can make an indigenous number cruncher. Take with mistrust: the channel length was 6µm when I left this activity. Marc Schaefer, aka Enthalpy aka Pointertovoid
-
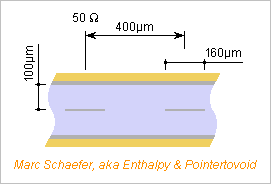
I claim to space the compute boards by 20mm, so here's a 8mm thin liquid cooler for the Lga2011. The preferred coolant would be the less flammable phytane, but only farnesane is mass-produced by Amyris and could also be obtained from Ocotea caparrapi resin chemicalforums I compute with Dowtherm A here, also called Therminol VP-1 and more, because it's better characterized. Melting Flash Boiling Capacity Density Capacity Conductivity Viscosity Coolant point point point J/kg/K kg/m3 MJ/m3/K W/m/K mPa*s ----------------------------------------------------------------------------------------- Farnesane <-79°C +109°C +242°C ~1900 ~750 1.43 0.13 few Phytane <-79°C +160°C? +296°C ~1900 ~765 ~1.45 ~0.13 few Dowtherm A +12°C +110°C +257°C 1658 1036 1.72 0.13 2.1 ----------------------------------------------------------------------------------------- To evacuate <=150W from the Lga2011, 8.7cm3/s unfrozen Dowtherm A enter at +35°C and exit at +45°C, or mean +40°C. With Re=1800, marginally laminar 1.2m/s in D=3mm waste only <<800Pa. 44 biface channels 35mm long and 5mm tall offer 1.5dm2 exchange area. In the laminar flow, heat crosses 0.3mm width /2/3 = 50µm, so 0.13W/m/K drop 3.7K to conduct 150W. The Re<100 laminar 8.7cm3/s flow peaks at 0.20m/s at the channels' center. The 18Mm/s/m2 curvature of the parabolic distribution lets 2.1mPa*s induce 37kPa/m gradient and waste only 1.3kPa over 35mm length. Cu-Cr, Cu-Zr or CuCr1Zr aged for yield >= 310MPa conduct >310W/m/K so the 44 fins 0.5mm wide and 35mm long drop 1.0K over mean 5mm/3 height. The 35mm*35mm base drops 0.6K over 1.5mm thickness. This design keeps the Cpu's top at +45°C (plus the paste's drop), huge margin. It can cool a 205W Lga3647 too, be thinner, have fewer thicker channels. A prototype can etch chemically the elements, or mill them if glued or soldered on a holder. Series production would stamp them. They can then be coated with a filler, Sn or other, and the stack soldered together with pressure, with here undisplayed end pieces for the mounting screws and the pipes. The base is finally milled flat. Marc Schaefer, aka Enthalpy aka Pointertovoid
-
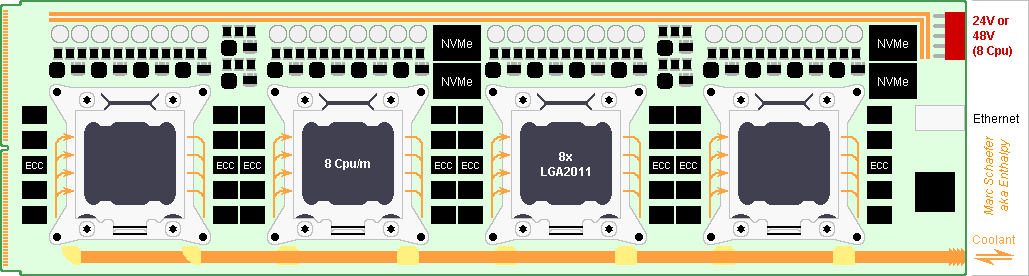
Some proposals are illustrated here. If it works, a Ddr4 Dimm connector shall pass 2*36 Pci-e lanes to the backplane. It's 142mm wide, so a backplane >1.15m tall hosts columns of 8 compute boards. The compute boads and its rails are thankfully taller. Narrow sockets exist for Bga2011. I considered only the square ones. Multichannel Dram needs dense routing while plugging in a connector a thin board: video cards combine both. If needed, make the board thinner locally. 2 Nvm-e per socket fit easily. The Qpi suffices for a Raid-5 among 4 sockets on one compute board, reading 10-20GB/s for any core successively. Very far from the golden rule, but virtual memory make sense again. Boards with fewer Cpu sockets can join more Nvm-e on Raid. One desktop power supply can feed a socket over a video card cable. A banal supply feeds one socket, a gamer's supply feeds two. Recycled ones are dirt-cheap. Connectors less ridiculous would save room. +12V/0V bars of 2mm*8mm copper feeding 4*150W drop only 6mV each for low ground noise. Connect the supplies' ground at their compute boards. Taylor-made shorter So-dimm were a bad idea. They gain only 50mm over a 1m board. Dram packages are soldered so one must buy them new. Searching better is necessary; in 1Q2023, I found 6usd for 8Gb or 4Gb Ddr4, 13usd for 16Gb, 52usd for twin-die 32Gb: digikey - mouser 4*16b+8b wide with Ecc take 5 packages *4 channels, or 120usd and only 16GB per Cpu socket. Recycled So-dimm cost 50usd for 16GB or 88usd for 32GB. More expensive and powerful Cpu sockets wouldn't get more Dram capacity, Dram speed, network speed. I dislike a compute board 2m long to carry 8*Lga2011, so Dram chips are soldered at the front and back of the compute boards, with the mentioned drawbacks. So are Nvm-e packages, at the rear too if thin enough. Maybe Nvm-e packages assemble several chips, then individual packaging saves height. 12V could provide 1200W and the rails carry them, but I prefer to connect desktop power supplies in series for 24Vdc or 48Vdc. Use a different connector model. But are the converter components cheap? I didn't recheck the diameter of the coolant pipes. The coolant pipes could also run over the socket's "Independent Loading Mechanism", one at each side. The pipes could carry the power too, good excuse for better connectors. 4*Lga2011 as drawn would use So-dimm. Please imagine the 8*Lga2011. Marc Schaefer, aka Enthalpy aka Pointertovoid
-
PCIe connectors limit the communications of a compute board to 16 bidirectional links. The CPU(s) would achieve more. DDR4 DIMM have 288 contacts. If a differential link takes 2 signals and 2 grounds, a DIMM connector passes 36 PCIe links. So a project could just experiment if DIMM connectors carry PCIe data cleanly. Simple, nice, useful, at a university or elsewhere. For the supercomputers that recycle computer parts, and more applications. Marc Schaefer, aka Enthalpy aka Pointertovoid
-
14 months later, did the second-hand server Cpu offer evolve, can we assemble a better supercomputer on my Pcb backplane? 09 January 2022 Tsmc produces at 5nm for Amd, Apple and the others. Amd and Arm architectures made server Cpu recently, none is three generations old, so I didn't find bargain Cpu. Intel more or less produce server Cpu at 14nm now: skylake, cascade lake, which bring the Avx-512. While Bga 5903 and Lga 4189 are still ruinous, used Lga 3647 are only expensive, they stick at Pci-e 3.0, but they access 6*Ddr4. Lga 3647 increase computing power and Ram speed, the cost more so, and the network speed not at all. I understand (do I?) Skylakes have two Avx-512 but run near half-speed on Avx. 1.5GHz isn't an official clock frequency neither: engineering sample? | # GHz 64b | # MT/s | W | W/GHz | Cy/T | @ Qpi | PciE ======================================================================= h | 12 2.2 (4) | 4 2400 | 105 | 4.0 (1.0) | 2.8 (11) | 2 | 3.0 REF i | 12 2.3 (4) | 4 1600 | 105 | 3.8 (1.0) | 4.3 (17) | 4 | 3.0 j | 16 2.2 (4) | 4 1866 | 140 | 4.0 (1.0) | 4.7 (19) | 8 | 3.0 ======================================================================= k | 24 1.5 (8) | 6 2666 | 150 | 4.2 (0.5) | 2.3 (18) | 8 | 3.0 NEW ======================================================================= h = Broadwell-EP Xeon E5-2650 v4. LGA2011 16usd. i = Ivy Bridge-EX Xeon E7-4850 v2. LGA2011 20usd. j = Haswell-EX Xeon E7-8860 v3. LGA2011 30usd. ======================================================== k = Skylake Xeon platinum 8160 ES. LGA3647 90usd. ======================================================== Cascade lake Found none affordable at claimed speed ======================================================== First # is the number of cores, GHz the base clock, 64b is 4 for Avx-256 and 8 for Avx-512. Next # is the number of Dram channels, MT/s how many 64b words a channel transfers in a µs. W is the maximum design consumption of a socket, called TDP by Intel. W/GHz deduces an energy per scalar or (Simd) computation. It neglects the small gains in cycle efficiency of newer Core architectures. Cy/T compares the Cpu and Dram throughputs in scalar and (Simd) mode, ouch! It's the number of cycles the cores shall wait to obtain one 64b or (Avx-256 or Avx-512) word from the Dram running ideally. Now 768 long compute boards carrying eight 8160 ES exploiting the Avx512 give peak 3.5PFlops on 64b, around rank 200 in the Top500 list top500.org/statistics/sublist Used 4GB Pc4-21300 Sodimm cost some 10usd, so 24GB complete the Lga 3647 for 60usd. No Ecc, is that reasonable? Then, if each compute node costs 8*(90+6*10) < 1800usd, procurement costs 1 to 2 Musd to the new manufacturer of supercomputer. Dirt cheap! Ssd on Nvme outperform Sata. 2TB and 5GB/s per compute node cost 200usd while 8*256GB cumulate 250usd, 4TB and 24GB/s. Marc Schaefer, aka Pointertovoid aka Enthalpy
-
Thoughts about the cables that connect the cabinets. Crosstalk seems low, like -40dB, at just 400µm stripline pitch for 100+100µm dielectric thickness. This needs double checking. 45mm cable width and 10 layers would carry 2*500 signals plus redundancy. The shield shall be grounded at the transmitter end and serve as a voltage reference at the receiver. All superconductors at 77K or 20K are brittle and excluded I think. This leaves NbTi and Nb below less pleasant 9K. Aluminium below 10K looks preferable: 1.5pOhm*m at easily available 99.9998% purity. Over a dielectric with very low loss at 10K it would transmit >40Gb/s over 30m at once. BUT the aluminium shield leaks too much heat from 77K to 10K at ends, even if 100nm thin there. The helium cooler would consume as much as the computing elements. Other heat leaks are manageable: the dielectric at the ends, the tubes with vacuum and Mli insulation for 30 cables. Data sources: NBS' technical note 365 [5.5MB] NBS' circular 556 Maybe many signals can use differential pairs and share one shield. But putting together the difficult design with helium, nitrogen, vacuum, stiff tubes... presently I clearly prefer cables at room temperature embedding 2-3 repeaters per metre. The design and operations constraints are lighter, and they consume less power. Marc Schaefer, aka Enthalpy
-
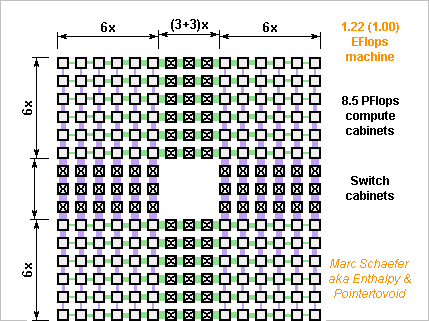
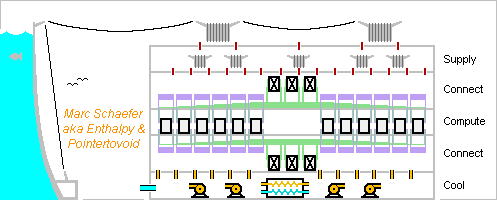
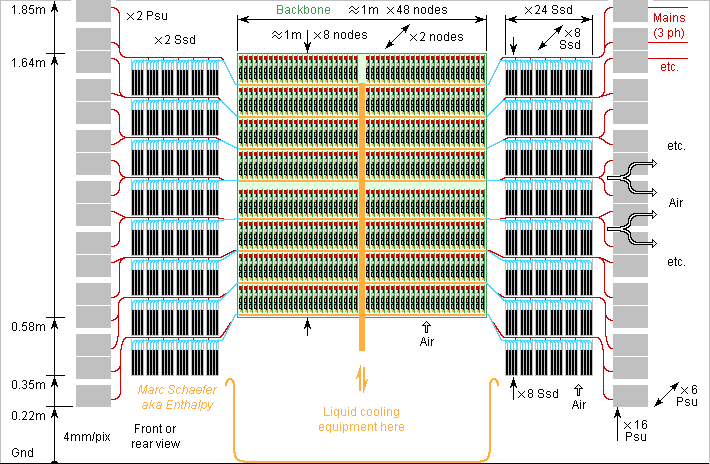
The US gov wanted in August 2015 an exaflops computer, but in January 2022 none exists: Fugaku achieved 0.442 EFlops on Linpack (64b). I proposed an architecture in November 2015, but meanwhile Cpu benefit from a 7nm process and Dram have grown scienceforums - msfn [Here just above] so here's a 2022 architecture for an exaflops computer. The just described eight 2.2GHz scalar Cpu stacked on 2GB Dram cumulate 70.4GFlops (64b, FMAdd, peak everywhere) and 422GB/s. Alas, I keep the 2015 network design, with narrow copper lines and thin insulator stacked as thick rigid Pcb or as loose multilayer flexible Pcb. Repeaters are needed, in the cables too - but they transmit every received bit immediately, of course, and don't wait for a complete packet. So do the switch matrix chips that route up to some 60 inputs to 60 outputs. Because the exaflops computer has fewer cabinets in 2022, the network's throughput drops to 70PB/s in each direction through any equator. That's one 64b word per scalar core every 70 cycles: much better than existing supercomputers, but far less than I'd like for easy programming. A copper line takes 0.5mm width pitch and 0.3mm thickness to carry several 10Gb/s. For the electric comms between the cabinets, I'd consider superconducting lines very seriously. Using capacitive coupling and chips, one 40mm*40mm connector transmits 2*500 electric signals. Fibres don't achieve that as far as I know. Usual plastic fibres are no competitors, thinner ones maybe, with coarse Wavelength Division Multiplexing over a few 10m. Monomode fibres seem better, if Dense WDM fits in a computer. I suppose a ribbon can integrate many fibers. Fibres would save the power-hungry repeaters. Fibre connectors are the limit: I didn't see nor imagine any small one. But if one fibre carries 500 wavelengths at 40Gb/s each, the connector can be Sma sized. WDM on plastic fibers over 100m, fibre ribbons, tiny connectors... would be useful research topics, not addressed by the research for Internet and needing disruptive improvements for computers. The compute boards integrate improved Dram and Cpu in same 40*50*2 amount and 2-D switch matrix organisation as on 22 November 2015 scienceforums and one compute cabinet stacks 60 horizontal boards, with previously described data vessels and capacitive connectors leading to vertical boards at the cabinet's back that make the 3rd dimension of the switch matrix. One cabinet cumulates 240 000 Dram for 480TB, 1 920 000 Cpu for 8.45PFlops. The 30 upper compute boards send data cables to an upper floor, the 30 lower to a lower floor, with each floor holding cables in X and Y direction which are the 4th and 5th dimensions of the switch matrix. Just 144=12*12 cabinets provide 1.22EFlops peak, which at 83% efficiency must be 1EFlops on Linpack, combined with 69PB and 15EB/s Dram, and hopefully much Flash memory speed. I can even display true item numbers this time. Each compute board carries 32 connectors, and the switch boards must route the signals among connectors at the same position on all 12 compute cabinets in a row or column on the floorplan. As switch boards carry 32 connectors, each can manage 2 connector positions at the compute board, so only 6 switch cabinets manage the 12 compute cabinets in a row or column. scienceforums - scienceforums While one floor is good for the compute cabinets at 1EFlops, cables better spread over two floors, and then the switch cabinets can too. US companies can produce the necessary chips. Marc Schaefer, aka Enthalpy aka Pointertovoid
-
One 4*2GB Hbm2 Dram stack reads 250GB/s, a true improvement over Dimm. So what computing power would it feed according to the golden rule? Two reads and one write over 64b take 24B transfers, so the throughput feeds 10G FMAdd/s. This suffices for: Avx-512 | | 1*1.3GHz Avx-256 | 1*2.6GHz | 2*1.3GHz Sse | 2*2.6GHz | 4*1.3GHz Scalar | 4*2.6GHz | 8*1.3GHz That's less processing power than a desktop. Worse for a supercomputer, it's little processing power per unit area, even if the Cpu can sit on the Dram somehow. At least, such a Cpu is easily made and it's frugal, even at 10nm. Depending on the Hbm2 latency, the Cpu still needs more or fewer caches. The Dram capacity is big at 2.6 Flops/Byte, so 4*1GB or 4*512MB would suffice if they provide the same throughput. ========== But what if a socket carries 8 Hbm2 Dram stacks around the Cpu? If the socket and Cpu handle the 2TB/s, the golden rule lets feed a small Cpu: Avx-512 | 4*2.6GHz | 8*1.3GHz Avx-256 | 8*2.6GHz | 16*1.3GHz Sse | 16*2.6GHz | 32*1.3GHz Scalar | 32*2.6GHz | 64*1.3GHz ========== Or the throughput must increase, as I proposed above.
-
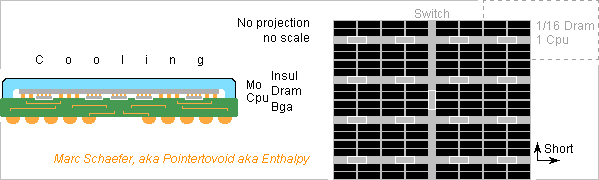
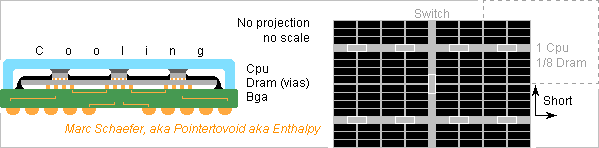
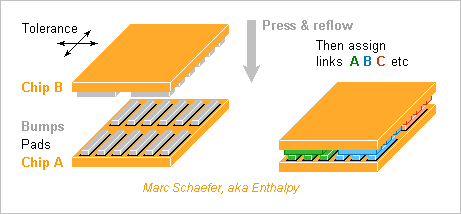
Chips progressed since my last check on 17 December 2018, so here's an update. ---------- Dram update The capacity only doubled in 3 years, to 2GB=16Gb per chip at Hynix (even 3GB), Samsung, Micron. Chips stack using Through-Silicon-Vias (Tsv). Fugaku has 100Flops/Byte because the faster Hbm2 on the processor socket limits the capacity. I won't imitate that. Other supercomputers offer 10-40Flops/Byte. I strongly advocate to spread the cores among the Dram for throughput and latency. One 2GB Dram can host 8 scalar cores (no Simd, one 64b FMAdd per cycle) at 2.2GHz for 18Flops/Byte. Each scalar core has comfortable 256MB Dram for OS subsets and application data. Or 16 scalar cores at 1.1GHz should save power. ---------- Flash update One 32GB Flash chip suffices for 2GB Dram. If a divided Flash chip stacked under the Dram can provide 600MB/s to each core, virtual memory saves the whole Dram in 0.4s, and data centers too improve a lot. If not, the 8 cores (or several sockets) can share a (stacked?) Flash socket nearby. ---------- Cpu update Intel is stuck at 14nm (10nm for chips not too big) and Amd buys its performance chips, but Tsmc produces 7nm processors, Samsung too. This improves the integation and power consumption over my latest update, and explains the Flops*2.6 from Summit to Fugaku: each A64fx Cpu socket holds 48 cores that compute sixteen 64b FMAdd (two 512b Simd) per cycle, while the whole Fugaku consumes 30MW or 0.24W per 64b FMAdd at 2.2GHz - maybe 0.15W locally. ---------- Divided Dram, split Cpu A divided Dram has a shorter latency. 8 sections, with address and data access at their centres, cut the distances by sqrt(8). Diffusion time over RC propagation lines explain the latency well, and then the latency is cut by (sqrt(8))2, so 50ns become 6-7ns, or some 15 Cpu cycles, excellent. The core needs only the L1 caches, no L2, no L3, saving almost 1/2 the silicon area. We could go further. 32 sections at 0.55GHz (waste silicon area) would slash the Dram latency to about 2 Cpu cycles to eliminate the L1 too. That's excellent for applications accessing random adresses, like Lisp or expert systems. Then instruction between 3 arguments in Dram, as the Vax-11 did, make sense again. To cut the distances on the Dram, each Cpu has its own chip and sits in the middle of a Dram section. Maybe some thick upper metal layers transport signals quickly on the Dram, but I doubt enough signals fit on the area. I expect many <1mm2 Cpu are cheaper than one huge many-cores. A 14nm or 10nm process can produce it at Intel etc, and then a slower clock and more Cpu would limit the consumption. Spare Dram sections can improve the production yield. A Bga socket suffices, I expect many ones come cheaper than one huge Lga. Cooling 8*0.15W is very easy. I displayed a switch matrix chip, the same as between the sockets, stacked on the Dram, but the Dram could integrate the function or the Cpu provide direct links. Stacking and splitting applies also to graphics cards, gamestations, desktops. Massive multitasking is necessary anyway and difficult enough. The scalar Cpu are easier to program and fit non vectorisable applications. I hope one sequencer per scalar Cpu is small and frugal. ---------- Dram to Cpu interconnect For easy programming, I want to restore the "golden rule": L1, L2... Dram throughput match the Cpu needs. Such a loop for (j blahblah) s += a[j]; or s += a[j] * b[j]; or even c[j] = a[j] * b[j]; can run within L1d of present processors, L2 of some recent ones, maybe L3, but not over the Dram, and this worsens over the generations. The older and smaller Xeon E5-2630L v2 computes on 4*64b (Avx-256) over 6 cores at 2.4GHz. a[j] needs 461GB/s, a[j] and c[j] too depending on the program. But 4*64b Ddr-1600 supply only 51GB/s. The Cpu must wait 9 cycles to obtain one a[j] from the Dram, or 27 cycles for a[j], b[j] and c[j]. The big Xeon Phi 7290 computes on 8*64b (Avx-512) over 72 cores at 1.5GHz. 6*64b Ddr-2400 take 60 cycles to supply one a[j], ouch. The recent A64fx get 1TB/s from HBM2 Dram on the socket, better. But 2*8*64b (two Avx-512) over 48 cores at 2.2GHz would need 14TB/s. The Cpu would wait 14 cycles for one a[j]. It's "Cy/T" in the table of 09 January 2022. To feed the Cpu, the programmer must find operations that use the data many times, write external loops that move data subsets to the caches and internal loops computing there. Slow L3 or L2 can demand intermediate loops. And some computations like an Fft just use data too few times. Separate Dram and Cpu create the horrible bottleneck at the worst place. HBM2 Dram on the Cpu socket improves too little. My answer is to stack a Cpu over each Dram chip and connect them densely. I explained there how to transfer enough signals scienceforums here's again the drawing. The chips carry solder islands smaller than we can align, and after reflow the chips assign adaptively the signals to the obtained contacts. The tiny islands consume little power to transmit the signals. Capacitive coupling can't supply power easily, alas. If Tsv were narrow enough, a stack of Dram could carry more Cpu. In my example, a scalar 64b core needs 3*64b transfers per clock cycle. With some links and power suply, that's 1000 contacts to the Dram at 2.2GHz (can be faster). If each contact takes (5µm)2, just (160µm)2 suffice on each Dram section and Cpu. Just 0.5µm etching suffice, even coarser at a demonstrator, and two Pcb make a poof-of-concept, so that's a nice university project. Ready? With estimated 15 cycles latency at 2.2GHz, the Dram can access data over only 15*3*64=2880b=360B to achieve the throughput. This relates with the L1 line size too. Close coupling between Cpu and Dram allow original useful accesses at full speed, as I described there scienceforums for (j blahblah) L1d[j] = Dram[j*n]; // Matrices, struct and many more or L1d[j] = Dram[bitreversed(j)]; // For FFT or also L1d[j, bits k] = Dram[k, bits j]; // For database filtering Dram access width being a prime number of bytes or words avoids most collisions in periodic addresses. Some primes like 28+1 or 211-1 simplify the hardware. Bit shuffling works best with transfer sizes multiple of 64 dwords of 64b. Marc Schaefer, aka Pointertovoid aka Enthalpy
-
I supposed it, now I'm convinced that hyperthreading is a drawback in a supercomputer. A desktop runs much single-task software that demands a fast clock, and then hyperthreading combines this nicely with occasional multitasking. But a supercomputer has always enough tasks to load all cores. In that case, twice as many slow cores are better than a hyperthreaded one. Hyperthreading provides 30% more speed by feeding the execution units with operations from two threads. Doubled execution units with clock 0.65* as fast do it too, and because each draws power like F2.4, together they consume 0.71* as much. Slower duplicated schedulers would also consume 0.71* as much, but since hyperthreading adds complexity, two slower simpler schedulers save more power. Each thread needs capacity at the cache memories, so each of the doubled execution units just needs its half of the L1i, L1d, L2, L3... The chip area for caches is identical. Two small caches may respond faster than a big one, depending on the design. Even if not, a core 0.65* as fast is stalled for 0.65* as many cycles by memory latency, including from the Dram. Two slower cores stall less hence run faster. Conceptually, a hyperthreaded core offers two register sets, but a core has about 180 dynamically renamed registers for parallelism, and this number depends more on the execution capability. So two slow cores would total more registers. The area is tiny anyway. The execution units keep as big each, so they total twice the area, which is small anyway. Unclear to me, as I'm out of this job for decades: how big is the scheduler. On pictures of vectored hyperthreaded chips, it seems huge. If hyperthreading less than doubles its complexity, two slow cores may need more area. But hyperthreading doubles at least the instruction decode, splitting in µOP and regrouping them. Summarizing: two slower cores may be slightly bigger or smaller together than a hyperthreaded one, they run faster and consume less. Whether someone will redesign a core just for one 1G€ supercomputer?
-
Thanks Tripredacus! I haven't looked at Ssd for some time and still use some on a Sata cable at home, but better interfaces seem to exist now. Sata is available without an enclosure. Pci-E delivers a throughput that fits the Ssd capabilities better. The designer of the compute boards might also buy new Flash chips and integrate them on the board. I didn't take time to compare the many options. In this particular use, Flash is still a bit slow to make a good virtual memory for a number cruncher, which can hence still use remote Ssd and Sata cables. But a database or a file server machine needs file performance, and for them the interface is paramount. The considered sockets have commonly 40 Pci-E 3.0 lanes each, of which 16 per computing board target the backplane Pcb. The other ones are available, and Flash throughput is among the very best uses to make of them.
-
The offer evolved since July 2019 so here's an updated selection of second-hand server Cpu to assemble a supercomputer or a mega-server on my Pcb backplane. I checked only Intel despite they stick at 14nm. Not Amd. Not used Arm Cpu. Horrible mistake? Still Pci-E 3.0 only, bad! Wider connectors (Dram?) may improve the network. A bigger Pcb backplane too. Newer Cpu still increase the tiny Dram bandwidth less than compute power. Ruinous LGA3647 bring 6*ddr4. Better twice as many LGA2011 sockets per board with 4*ddr4 each. Ruinous Skylake, Cascade Lake bring Avx512. Better twice as many Avx256 sockets per board. Time squeezes prices. I report reasonably good bargains for small amounts on eBay. In July 2019 it cost 40€, the E5-2630L v2 costs 20€ now. The E5-2650 v4 brings 1.5* E5-2630L v2 except for Pci-E (*1) and price (*2). 4 or 8 server Cpu on one computing board can share the chipset and Bios and are affordable. Alas, they must share the network. | # GHz 64b | # MT/s | W | W/GHz | Cy/T | @ Qpi | PciE ======================================================================= d | 6 2.4 (4) | 4 1600 | 60 | 4.2 (1.0) | 2.3 (10) | 2 | 3.0 REF h | 12 2.2 (4) | 4 2400 | 105 | 4.0 (1.0) | 2.8 (11) | 2 | 3.0 <== ======================================================================= i | 12 2.3 (4) | 4 1600 | 105 | 3.8 (1.0) | 4.3 (17) | 4 | 3.0 ======================================================================= j | 16 2.2 (4) | 4 1866 | 140 | 4.0 (1.0) | 4.7 (19) | 8 | 3.0 ======================================================================= d = Ivy Bridge-EP Xeon E5-2630L v2. LGA2011 20€. h = Broadwell-EP Xeon E5-2650 v4. LGA2011 40€. i = Ivy Bridge-EX Xeon E7-4850 v2. LGA2011 30€. j = Haswell-EX Xeon E7-8860 v3. LGA2011 40€. ================================================ First # is the number of cores, GHz the base clock, 64b is 4 for Avx-256 and 8 for Avx-512. Next # is the number of Dram channels, MT/s how many 64b words a channel transfers in a µs. W is the maximum design consumption of a socket, called TDP by Intel. W/GHz deduces an energy per scalar or (Simd) computation. It neglects the small gains in cycle efficiency of newer Core architectures. Cy/T compares the Cpu and Dram throughputs in scalar and (Simd) mode, ouch! It's the number of cycles the cores shall wait to obtain one 64b or (Avx) word from the Dram running ideally. So 768 compute boards carrying two E5-2650 v4 give you 0.32 PFlops (64b, Fmadd, Simd, peak). Four E7-4850 v2 give 0.68 PFlops. And eight E7-8860 v3 on long compute boards give 1.7 PFlops, at the edge of the Top500 supercomputer list, but with a better network. Marc Schaefer, aka Enthalpy
-
Hello you all! Nice to meet you again. I had described how to assemble a small cheap supercomputer from used server parts, there: scienceforums and around I reuses second-hand Xeons E5-2630L v2 for instance, laptop Ddr3, Ssd with Sata (bad choice?), Atx power supplies. The computing Pcb (up to 768) are specially designed, as is the 1m2 many-layers Pcb backbone. Pci-E signals and connectors make a network whose 3TB/s through any equator outperform existing supercomputers of same computing power. The network uses specially designed chips that make dense interconnection matrices from 32 to 32 Pci-E lanes. They build a superior bidimensional matrix scienceforums Such chips exist already but may not be commercially available and too expensive to redesign; then, a hypertorus avoids the matrices but slashes the performance by 3. From 0.25M€ hardware cost, you get 88 TFlops (peak, 64b, Fmadd) with less bad Dram throughput, superior network throughput, decent consumption. Very nice university project, both to develop and to use - and possibly to sell. ========== Now with A64FX I just checked the performance with a recent Cpu, the Arm-Fujitsu A64FX, four of them per computing Pcb, 3072 in total. The same backbone still provides as much throughput per Cpu as the Fugaku supercomputer does, so it's usable. The 2m*2m*2m cabinet then crunches 10 Pflops, enough for the 70th position in the supercomputer Top500 list A64FX – Fugaku – TOP500 on wikipedia Nov 2011 list on top500.org All intermediate designs are possible, say with four second-hand less old Xeons or one A64FX per computing Pcb... So, plug the soldering iron? Have your very own supercomputer? Marc Schaefer, aka Pointertovoid aka Enthalpy
-
Thanks Jaclaz! I'd need more evidence before involving little green men in this story (or elsewhere). And I'd like to know why a mobo with a new battery should lose the date. Or even two mobos. So I'm still interested in testimonies: did other people observe an abnormal clock reset on their mobo? Thank you!
-
Hi everybody, nice to see you again! I had imagined that resetting a computer's clock might be a way to weaken its encrypted communications, especially if they are as poorly programmed as what the cited webpage gives as an example. Recently at my close relatives, two computers have shown abnormal clock resets. At my old mother, the Cmos' battery was empty. I replaced the battery with a new one from a reputed brand bought in a closed package a quarter hour before, I set the clock, and the computer worked properly. A week later, this computer lost the date again. The computer was far from me, I got the account over my mother. At my nephew, who is comfortable with Pc hardware and can replace a battery, the computer with a recent battery lost the date. I had expected a reset date like 01 Jan 2000 or 01 Jan 1970, as usual with an empty battery, but at my mother's machine it was like 31 December 2001. So: did you observe something similar recently? The alternative explanation would be a malware that sets the computer's clock, possibly to exploit the weakness I outlined above. I could admit a hardware defect drawing the battery empty at one mobo, not at both. Thank you!
-
CFast, your thoughts?
pointertovoid replied to pointertovoid's topic in Hard Drive and Removable Media
Thanks Jaclaz! Yes, that's about what I plan. I had already good Apacer Cf, though I didn't use them for very long. Good experience with Transcend EXCEPT that in their 300x 8GB, they put Mlc chips without warning and contrary to their datasheet that promises Slc. Recently, two Toshiba 32GB 1000x went broken at the same time on two different readers - still not understood, maybe a high-tech Usb virus. So I consider Sata instead of Usb. I already had an adapter, or cartridge, for Ssd on Sata. My bad experience is that the connectors went broken after months, with random bad contacts. Avoid them, everybody - unless someone can report a good specimen he used for an extended period. Meanwhile, I connect and remove my Ssd on plain long cables daily, without a cartridge, and this is reliable over years. So I hope to do the same with Cfast, as I do need a smaller format than Ssd. My main concern would be some incompatibility between signalling voltages or a similar bad joke that plagues Cf cards. You know, Pata ports in 5V and some Cf cards that need 3.3V for Udma, or even fail to transmit properly on 5V. More reports, opinions, comments? -
Hello everyone and everybody, nice to see you again! I consider switching from CF (on USB reader) to CFast Flash cards. Has someone experience with them? From what I understand, the electric interface is Sata/6000 or Sata/3000 but the connector differs, needing an adapter card. Correct? Is there any bad joke with Sata and CFast, like the varied signalling voltages that plague CF cards? I plan to buy some Chinese adapter card, as they comprise essentially two connectors and copper lines in between, plus seemingly a regulator. Thoughts? The CFast cards I covet have 32GB and Sata/6000, my mobo has Sata/3000 from Intel's ich10r, ran with W2k and Xp, maybe Seven some day if needed. Opinions? I can live without the hot plug and unplug, and have some 3rd party software to force-eject a disk. Other thoughts? Thank you!
-
LBA-48 Support for Windows NT 4.0 and slipstream SP6a
pointertovoid replied to WinFX's topic in Windows 2000/2003/NT4
My answer is late and sketchy, sorry... I only tried Nt4 briefly, so this is more repeating what I've read than first-hand experience. Most slipstream tools for 2k and later base on the slipstream capability that Microsoft built in the updates. This did not exist for Nt4. Nevertheless, some enthusiasts did write software to slipstream updates into Nt4, including the Sp6a. Do I remember that at least 3 such exist? I don't have my notices here. I saw a workaround, using an F6 diskette, to provide Lba access to a disk right from the beginning of an installation. Possibly a servicepacked version of acpi.sys on the diskette, plus some text files telling to use it. Whether this can provide Lba48 too? My answer may be 40dB behind what you already know... Apologies in advance. -
CPU Kernel Page Table Isolation bug disclosure
pointertovoid replied to Monroe's topic in Technology News
Not necessarily. The weakness results from the CPU restoring imperfectly its state when an exception occurs. Speculative execution makes restoration difficult, but alone it doesn't imply a weakness. From Intel's list, the Core 2 for instance seems immune, with the design flaw beginning at Core i3/i5/i7. I trust Intel's list (...which can evolve) better than arbitrary claims from other sources, which often rely only on the presence of speculative execution, a very old feature indeed. I wonder: exceptions occur much more frequently than after a violation of memory protection, including during legitimate operation of the OS and applications. If the restoration of state is faulty, then the CPU must introduce erroneous behaviour in the machine. This hasn't been observed before? -
Microsoft patches Windows XP to fight 'WannaCry' attacks
pointertovoid replied to Jody Thornton's topic in Windows XP
In the very few past hours, eBay and Paypal show the same symptoms of bad operation as during the two last attacks by Wannacrypt and its successor. Just in case a new wide attack has started, take your precautions! -
I've just tried on a 32 bits Windows Seven that I installed minutes before alone on its disk. I suppose the session has administration rights because it accesses the Device Manager. Nearly the same happens as with W2k and Xp. Minor change: Seven installs its v6.1 driver when I insert a CF and runs long enough to show me it comprises disk.sys and partmngr.sys, after what it freezes too. Disconnecting then the reader doesn't heal.
-
Meanxhile I've had a Firewire 400 (1394a) reader from Lexar. It worked right after connecting to my mobo (chip TI Tsb43ab23), without adding drivers, on W2k-Xp that brought the OHCI drivers, and on Linux (Ubuntu 14, GPartEd and others). Said to be fast, but it was slow on my computer. I can't exclude that Lexar changed the chip over time. Sold again. I've just received a FW800 (1394b) card on Pci-E and a CF-card reader on FW800 and they don't work. Please help! ---------- The Pci-E card is a new Iocrest SY-PEX30016 with a TI chip XIO2213BZAY. Both W2k and Xp install their OHCI driver which is said to suffice for FW800. Everything looks fine in the device manager, as described by Iocrest. I also tried the Unibrain Firewire driver on W2k, it installs too and the device manager shows it. Linux starts with the card, I can't analyze more. The CF reader is a Sandisk extreme Firewire SDDRX4-CF bought used from a Mac user who claims it works. About zero doc available from Sandisk, I shall remember that. If I connect the reader when the OS runs, no additional disk reader is shown by Win nor Linux, but they run. Same if I boot the OS after connecting the reader. If I insert a CF (both 32GB UDMA 7 and 4GB UDMA 4, both formatted), the device manager refreshes after 10s as it uses to when detecting a new hardware, then Windows freezes but Linux doesn't; the device manager and task manager stop before the applications. I have no time to access the Disk manager. The Cpu fan doesn't accelerate. If I insert the CF then connect the reader to the running machine, the same happens as if inserting the CF. If booting with the reader and the CF, both Windows and Linux freeze. The Unibrain driver does nearly the same: it fails some seconds later, giving time to see on the device manager that Windows tried to install a disk driver but failed. ---------- I suppose that the new FX800 card is sound, as it gets its driver and detects the reader. A sound SDDRX4-CF is rumoured to work with Windows 98-Seven with the built-in drivers and shouldn't freeze Linux. Comments, ideas, suggestions, explanations...? I'm in the mood of returning the reader to the seller but wouldn't like to be unfair.
-
Recommended Wiping tool/method for hdd
pointertovoid replied to allen2's topic in Hard Drive and Removable Media
You can see some images where the magnetic polarisation is read at a small scale, for instance here http://aip.scitation.org/doi/full/10.1063/1.4944951 especially the Fig. 5 http://aip.scitation.org/na101/home/literatum/publisher/aip/journals/content/adv/2016/adv.2016.6.issue-3/1.4944951/production/images/large/1.4944951.figures.f5.jpeg at a perfect scale for hard disk drives.